Ketika sebuah aplikasi tumbuh besar — misalnya platform e-commerce, media sosial, sistem perbankan online — beban database menjadi sangat tinggi. Query baca dan tulis tak lagi ringan. Salah satu cara umum untuk menjaga performa dan skalabilitas adalah dengan menggunakan database cluster. Salah satu model cluster yang populer adalah master-slave replication (atau kadang disebut primary-replica). Dalam arsitektur ini, ada satu node database yang bertindak sebagai master untuk semua operasi tulis (writes), dan satu atau lebih node slave yang mereplikasi data dan melayani operasi baca (reads).
1. Konsep Dasar Master-Slave Replication
Pada arsitektur master-slave, data ditulis (INSERT, UPDATE, DELETE) hanya ke node master, sementara node slave menerima salinan update dari master dan bisa digunakan untuk operasi baca (SELECT). Dengan demikian beban baca dapat dibagi ke banyak slave, sementara master tetap menjadi sumber tunggal pembaruan data.
Terminologi database cluster master-slave
- Master / Primary: Node utama yang menerima semua write. Membuat log (binary log di MySQL) dari semua perubahan.
- Slave / Replica: Node yang mendengarkan log dari master, memproses log tersebut, dan menerapkan update sehingga data menjadi mirror dari master (atau mendekati mirror).
- Replication Lag: Waktu tunda antara perubahan pada master dan kapan perubahan itu muncul di slave.
- Failover / Promotion: Bila master gagal, salah satu slave bisa dipromosikan menjadi master baru (manual atau otomatis).
- Read Scaling: Memindahkan sebagian besar query baca ke slave agar master tidak terbebani.
Arsitektur ini memungkinkan penggunaan node slave agar beban baca aplikasi tidak membebani master secara langsung.
2. Topologi & Cara Kerja
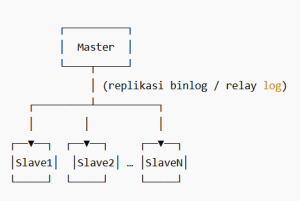
Database Cluster
Arsitektur bisa lebih kompleks — contohnya cascading replication, di mana master menyalin ke slave A, lalu slave A menyalin ke slave B, dan seterusnya.
Alur Replikasi (MySQL sebagai contoh)
- Saat transaksi commit di master, perubahan dicatat ke binary log (binlog).
- Slave terhubung ke master dan membaca binlog melalui IO Thread — menyimpan ke relay log lokal pada slave.
- Slave menjalankan SQL Thread untuk membaca dari relay log dan menerapkan perubahan ke database slave.
- Slave kemudian diperbarui sesuai dengan urutan log master.
Ada dua thread penting di slave: IO thread dan SQL thread.
Jika IO thread tidak bisa membaca (misalnya master mati), maka replikasi terhenti. Jika SQL thread gagal menerapkan log (misal error syntax atau constraint), maka slave bisa berhenti atau skip tergantung pengaturan.
Mode Replikasi: Sinkron vs Asinkron
- Asinkron (Asynchronous Replication). Master tidak menunggu konfirmasi dari slave sebelum commit berhasil. Ini cepat, tapi slave bisa tertinggal (lag).
- Sinkron (Synchronous Replication). Master menunggu setidaknya satu atau beberapa slave mengkonfirmasi bahwa mereka telah menerima perubahan sebelum commit dianggap selesai. Lebih aman tapi lebih lambat (latency meningkat).
- Semi-sinkron. Kompromi: master menunggu paling sedikit satu slave mengkonfirmasi bahwa ia sudah menerima (tapi mungkin belum menerapkan) sebelum commit dianggap sukses.
MySQL / MariaDB mendukung replikasi asinkron dan semi-sinkron (bila aktifkan plugin semi-sync). Replikasi sinkron biasanya ada di sistem cluster khusus seperti Galera atau MySQL NDB cluster.
3. Kelebihan & Kekurangan
Kelebihan
- Skalabilitas baca (Read Scaling). Banyak slave bisa menangani query SELECT secara paralel.
- Backup yang tidak mengganggu. Kita bisa backup atau menjalankan report di slave, sehingga master tidak terganggu.
- Redundansi / Failover (opsional). Jika master gagal, bisa promosi slave menjadi master agar sistem tetap berjalan.
- Isolasi beban baca dari tulis. Operasi tulis tidak terlalu terganggu oleh query baca besar di aplikasi.
- Pemisahan read & write di aplikasi. Aplikasi bisa diarahkan untuk SELECT ke slave, INSERT/UPDATE ke master, optimasi.
Kekurangan
- Bottleneck pada master write. Semua operasi tulis tetap melalui satu master → jika volume tulis tinggi, master bisa kewalahan.
- Replication lag / keterlambatan. Slave mungkin tertinggal. Jika aplikasi membaca data segar segera setelah tulis, bisa melihat data lama.
- Konsistensi lemah (eventual consistency). Karena lag, slave tidak selalu konsisten real-time.
- Promosi & failover kompleks. Jika master mati, harus ada logika failover yang aman agar data tidak hilang atau conflict.
- Biaya jaringan / beban I/O. Master harus mengirim log ke semua slave → beban bandwidth & disk I/O.
- Operasi administratif lebih rumit. Menjaga topologi, monitoring lag, sinkronisasi ulang slave jika gagal, dsb.
4. Kapan & Di Mana Cocok Digunakan
Master-slave cocok ketika:
- Aplikasi read-heavy: lebih banyak operasi baca dibanding tulis. Misalnya ecommerce (browsing produk, mencari, menampilkan katalog).
- Aplikasi toleran terhadap konsistensi eventual (tidak butuh data realtime penuh setiap saat).
- Anda ingin mengurangi beban baca dari master agar transaksi tulis tetap cepat.
- Anda ingin isolasi beban backup & reporting ke slave agar tidak mengganggu aplikasi utama.
Namun, apabila aplikasi write-heavy, atau butuh konsistensi tinggi real-time (misal sistem keuangan sensitif, ledger), maka arsitektur master-slave saja mungkin kurang memadai.
5. Tantangan Umum & Solusi
5.1 Replikasi Lag dan Konsistensi
Masalah:
Slave tertinggal dari master.
Solusi:
- Gunakan semi-synchronous agar master minimal menunggu satu slave menerima.
- Pada operasi kritis (misal baca stok setelah checkout), arahkan baca ke master.
- Pantau lag (monitoring), dan lakukan alert ketika lag melewati threshold.
- Hindari beban berat di slave yang membuat SQL thread tertahan.
5.2 Failover & Promosi Slave
Masalah:
Master rusak → sistem down jika tidak ada failover.
Solusi:
- Gunakan tool orchestrator (MySQL Orchestrator, MHA, Orchestrator) untuk otomatisasi failover.
- Rekonfigurasi aplikasi agar mengenali master baru (misalnya via floating IP atau DNS).
- Pastikan slave yang dipromosikan memiliki data lengkap (tidak tertinggal banyak).
- Lakukan pengecekan integritas data setelah promosi.
5.3 Penulisan dan Konflik
Master-slave model tidak memfasilitasi penulisan paralel (hanya satu master). Jika ingin banyak master (multi-master), risiko konflik muncul (dua master tulis data yang sama) → perlu resolusi konflik, sistem transaksi terdistribusi, dsb.
5.4 Beban Logging & I/O di Master
Setiap perubahan harus dicatat di binlog dan dikirim ke slave → semakin banyak slave, beban master semakin besar.
Solusi:
- Batasi jumlah slave yang langsung terhubung ke master — mungkin gunakan cascading replication (master → slave A → slave B → slave C).
- Gunakan hardware yang kuat (I/O tinggi, SSD, jaringan cepat).
- Gunakan kompresi log dan optimasi binlog_format (ROW, MIXED) secara tepat.
5.5 Pengelolaan Skema / Migrasi
Jika Anda perlu mengubah skema tabel (ALTER TABLE), harus memastikan perubahan di master dan slave tanpa downtime besar. Teknik seperti online schema change atau pt-online-schema-change bisa membantu.
6. Contoh Studi Kasus / Implementasi
Misalnya Anda memiliki aplikasi e-commerce:
- Master: menyimpan semua update stok, order, transaksi.
- Slave 1, Slave 2: melayani query produk, katalog, riwayat pembelian pengguna. Aplikasi memisahkan koneksi baca dan tulis: Semua SELECT diarahkan ke salah satu slave (round robin atau load balancer). Semua INSERT/UPDATE/DELETE ke master.
- Jika master mati, slave terbaik dipromosikan jadi master sementara (manual atau otomatis), dan aplikasi diarahkan ke master baru.
Contoh konfigurasi MySQL / MariaDB untuk replikasi master-slave dapat mengikuti dokumentasi MariaDB: master-slave replication enables data dari server master direplikasi ke server slave.
MariaDB
Dalam produksi, banyak orang menggunakan tool seperti MHA, Orchestrator, atau ProxySQL agar aplikasi tidak perlu mengurus logika failover sendiri.
7. Tip dan Best Practice
- Gunakan semi-synchronous replikasi bila konsistensi penting, tapi pertimbangkan toleransi latensi.
- Pisahkan koneksi read/write di aplikasi dengan layer abstraksi (connection manager).
- Pantau replication lag dan buat alert threshold (misal lag > beberapa detik).
- Jangan banyak slave langsung ke master — gunakan cascaded replication jika perlu.
- Uji skenario failover & recovery secara berkala.
- Backup secara konsisten dari slave agar tidak mengganggu master.
- Gunakan hardware & jaringan berkualitas (disk cepat, NIC cepat, latensi rendah).
- Gunakan versi MySQL / MariaDB terbaru agar mendapatkan fitur replikasi yang lebih baik.
- Jangan lupa enkripsi & keamanan koneksi replikasi (SSL/TLS), serta pembatasan hak akses user replikasi.
- Rencanakan migrasi skema (ALTER TABLE) agar tidak menyebabkan downtime berat.
8. Evolusi & Alternatif: Master-Master, Sharding, Cluster
Master-Master (Multi-Primary)
Dalam konfigurasi master-master, ada dua (atau lebih) node yang dapat menerima write. Semua node saling mereplikasi. Keuntungannya: tidak ada satu titik tunggal untuk write. Namun, masalah muncul seperti konflik (dua master menulis data yang sama), konsistensi, dan kompleksitas algoritma replikasi. (Wikipedia)
Biasanya digunakan bila beban tulis sangat tinggi dan aplikasi dapat menangani konflik atau menggunakan mekanisme resolusi custom.
Sharding (Partitioning)
Sharding memecah data ke banyak cluster master-slave, berdasarkan kunci tertentu (user_id, seller_id, dsb). Dengan demikian beban write dan read bisa didistribusikan ke banyak shard. Sharding + master-slave adalah kombinasi yang umum pada sistem berskala besar.
Cluster Khusus / NDB / Galera / MySQL Cluster
Beberapa sistem menawarkan cluster database yang otomatis melakukan replikasi sinkron / multi-master tanpa perlu logic aplikasi sendiri. Contoh: MySQL Cluster (NDB), Galera Cluster, atau sistem distributed SQL seperti CockroachDB, TiDB, YugabyteDB. MySQL Cluster misalnya mendukung auto-sharding dan replikasi sinkron antar node cluster. (Wikipedia)
Kesimpulan
Arsitektur master-slave replication adalah solusi yang relatif sederhana dan terbukti untuk meningkatkan skalabilitas baca dan memberikan redundansi dalam banyak aplikasi. Namun, ini tidak tanpa keterbatasan — khususnya terkait beban tulis, replikasi lag, dan kompleksitas failover.
Untuk aplikasi berskala besar (jutaan pengguna, transaksi tinggi), biasanya diperlukan kombinasi strategi: master-slave + sharding + caching + load balancing + failover otomatis. Jika beban tulis sangat tinggi atau konsistensi kuat sangat penting, maka alternatif seperti multi-master atau cluster database terdistribusi dapat dipertimbangkan.
Pingback: Implementasi Database Cluster Master Slave dengan PHP MySqli - Tutorial
Pingback: Kombinasi Database Cluster Master Slave dan Sharding Database untuk Solusi Jutaan Data - Tutorial
Pingback: Contoh Implementasi Sharding Database dengan PHP & MySQLi - Tutorial